Trip report: RDA 14th plenary (Joao Moreira)
14th plenary summary: 22-25 October 2019, Helsinki
João Moreira, PhD - postdoc researcher VU Amsterdam/U.Twente - FAIR Workflows
This 14th edition received around 600 people and almost all sessions were transmitted on-line, most of them with full-capacity. The researchers vary from different fields (e.g., health, agriculture) and information science professionals, e.g., librarians and data stewards. Recognized researchers in research reproducibility attended. You can find information on the past, upcoming and future Plenaries on the RDA Web site under the Plenaries tab.
The sessions are proposed by the interest groups (short-term - 18 months, 66 current) and working groups (open-ended, 36 current): “They focus on solving a specific data sharing problem and identifying what kind of infrastructure needs to be built. Interest Groups can identify specific pieces of work and start up a Working Group to tackle those”.
-
Sessions (14th): https://www.rd-alliance.org/rda-14th-plenary-programme
The sessions were either a group session, a joint meeting or a BoF (birds of a feather) session. BoF = the topic discussed “is sufficiently distinct from the work of existing groups or BoFs held at recent plenaries”.
On average, each session takes 1h30min and follows a similar approach with presentations during the first 1h and open discussion for 30min. Some sessions were quite dynamic with work groups discussing some specific task/topic, such as e.g. in the Management of Computational Notebooks with the Notebooks and FAIR digital objects topic.
I participated in this topic group giving information about the current status of the project (about to publish a preprint with OpenPREDICT use case), highlighting one of the gaps that we’re trying to address: “There are more steps than are in the notebook. Manual steps.”
As an early career grantee, I was assigned to support these sessions:
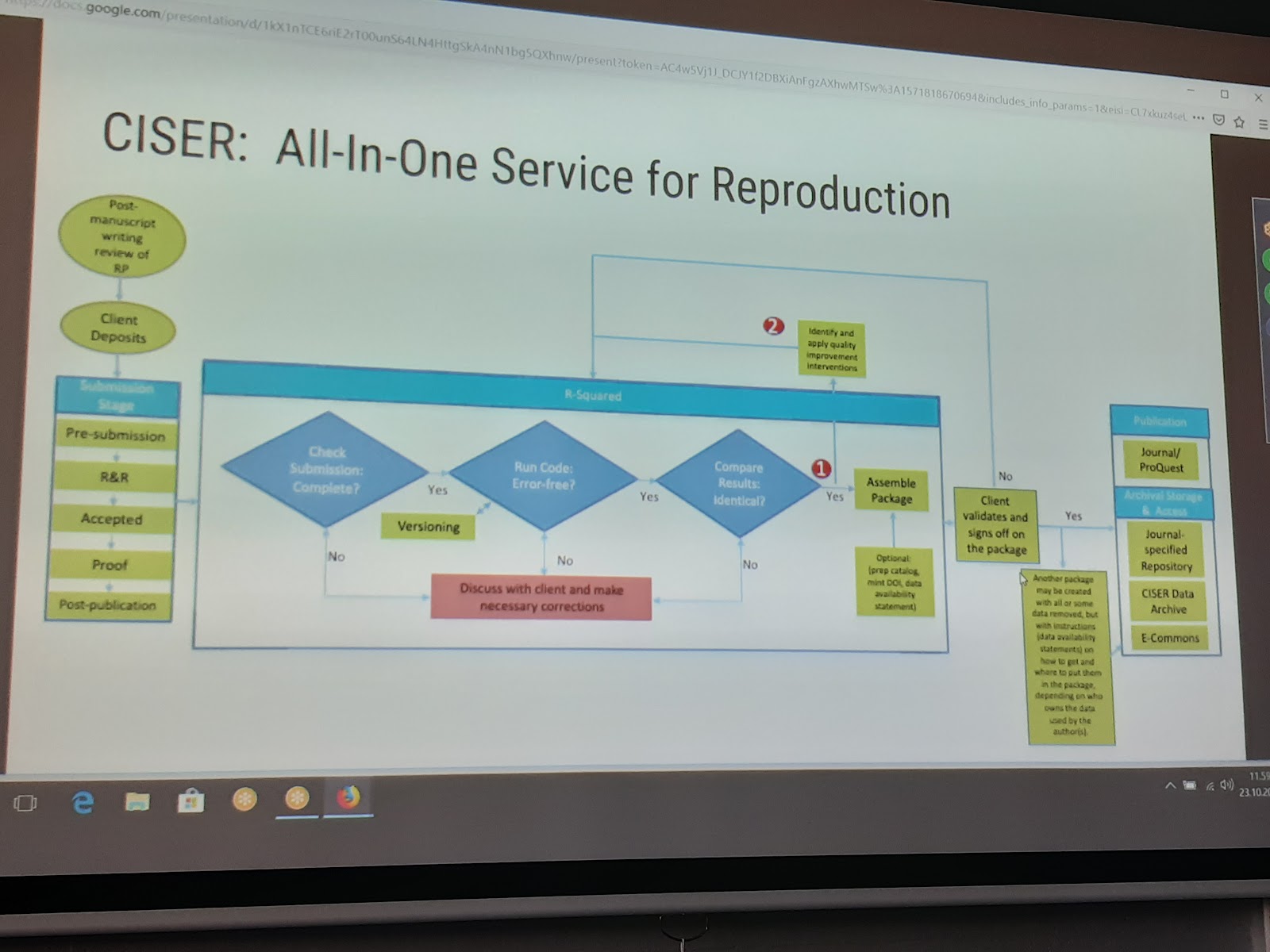
It was presented the CISER Workflow all-in-one Reproduction, where librarians are responsible for assessing the data and code linked to publications.
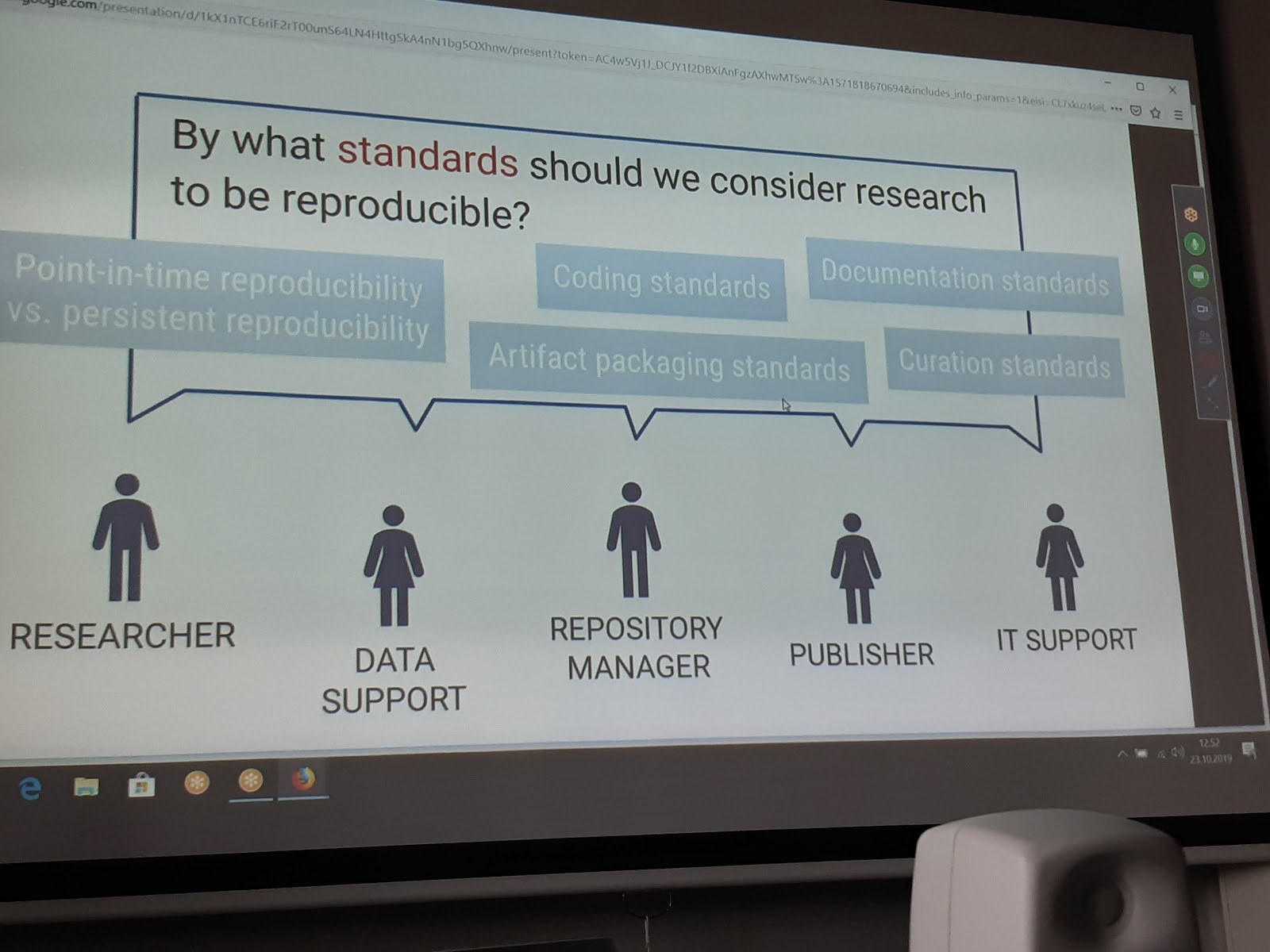
Q/A:
- This type of workflow is quite common in software engineering enterprises/consultancies during project delivery/validation: through e.g. test-driven dev approach, functional test cases, non-functional tests, unit tests, etc. Quite advanced on automating it.
- What is the impact to the publication process in terms of time?
- When you change the relative paths, you’re changing the code to some extent…
- “Establish standards”
Open notes: https://docs.google.com/document/d/1IenuTqrcIK-ktBkohr1ypvGkTjXmhCcSOLHLhaAX8Qg/edit#
Although it was the last session of the plenary, it had a relevant frequency (over 20 people), interested on best practices for making their ontologies FAIR.
https://docs.google.com/document/d/1AysoK2w9v45UdGu_TzXglO31J541hXcdne9W3GDMR9I/edit#
- Semantics = common definition from LD (OWL/logics)
- Idea of FAIRer ontologies: develop according to the FAIR principles
- FAIR recommendations + FAIR assessment
- Observable property terminology: W3C standards (SSN/SOSA -> O&M)
- Interpreting the Findable principles from the semantics perspective:

- https://github.com/sifrproject/MOD-Ontology
Metadata for Ontology Description and Publication Ontology
This project consists in building an OWL ontology and application profile to capture metadata information for ontologies, vocabularies or semantic resources in general.
MOD is an OWL ontology to capture metadata information for ontologies. It is a follow-up to the OMV2 Ontology project. This project is connected to the work done by @jonquet and @antool on a new ontology metadata model implemented within AgroPortal (https://github.com/agroportal): https://github.com/agroportal/documentation/tree/master/metadata
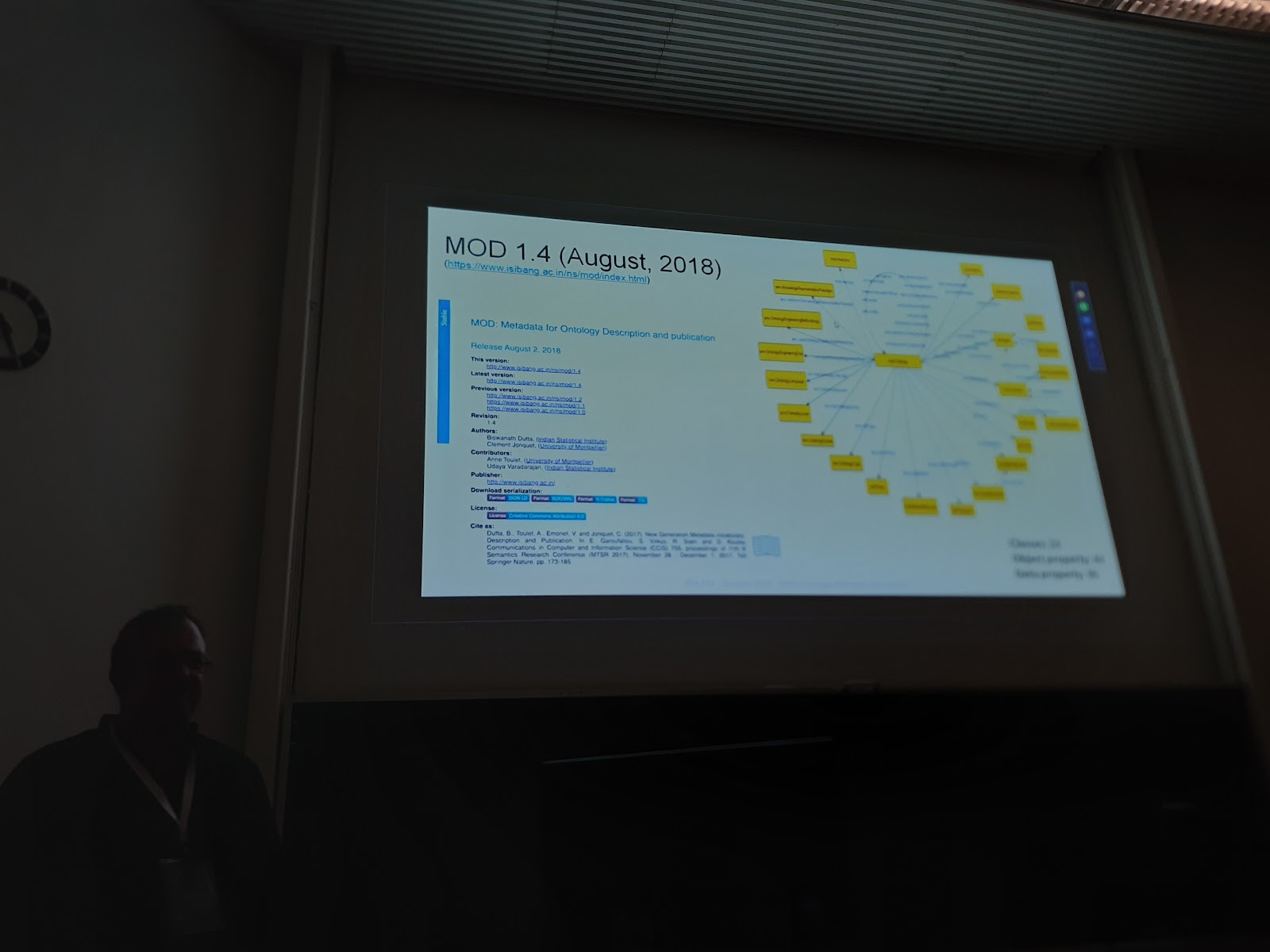
- Survey ontology metadata practices:

- Semantic artefacts:

Open plenary ("keynotes"):.
- Open data:

- Concept of computational reproducibility:



There were poster sessions. The 104 posters were organized on these categories: (1) Data Management Plans (DMPs), (2) Research Data Management, (3) FAIR Data, (4) Agricultural Sciences & Environmental/earth sciences, (5) Publishing/Journals/Citation, (6) Archiving / Repositories / Storing / Sharing, (7) Systems/Tools, and (8) Regional nodes (including RDA Netherlands and RDA Brazil). I presented a poster about our project (#44, presented in ICT Open 2019). Poster available here:

It took my attention the poster below, which received the best poster award (“the good, the bad and the ungly”) because of the ontology engineering best practices, under “focus naming” section:

This poster is based on this paper. I think that the highlighted best (and bad) practices are correct, aligned to our research on ontology engineering and how we’re developing the ontology within the FAIR Workflows project. I only highlight that using SKOS is a good option but there are other top-level (“foundational”) ontologies that can be used instead (or together), such as DOLCE UltraLite, BFO, or UFO/OntoUML. We also experience the “ugly” regarding the challenge of partial reuse of existing ontologies.
In my opinion, this plenary format is more convenient for collaboration and discussions than the classic conference format. In particular, RDA showed to have a consistent way of organizing and promoting the plenaries, making different communities (a huge diversity of profiles) to communicate and exchange experiences about research reproducibility. In general, the challenges discussed on data sharing are already well-known, the main difference is the approach oriented to large scale research. The importance of interoperability was often highlighted in the sessions and cross-domain interoperability for research data management was pointed as a relevant topic to be addressed by long term initiatives, such as the recent GO INTER (under the GO FAIR initiative).
The European Commission is participating closely in RDA events, taking the outputs as drivers for future research:


Some daily annotations
- 22nd (Tuesday)
-
Organized in 2 parts: FAIR repositories and FAIR semantics
-
FAIR repositories: approaching the “harmonization of the APIs”
-
Presentation FAIRsharing.org (Peter McQuilton): evaluation procedure for producers with new ontologies (terminologies). It indexes 1322 standards, which may be FAIR or not ⇒ big challenge: how to evaluate the FAIRness of ontologies/vocabularies? Needs further exploration.
-
FAIR repositories section
-
FAIRsharing.org: what is the role in FIARification process? Support on semantic modelling task to find existing predicades (tools to support)
-
- Semantic repositories (CEDAR): focus on interoperability
-
FAIR Data Point: difference between current semantic repositories to "FAIR metrics-oriented" (to pass in FAIR metrics)? Needs further exploration.
-
Outcomes for other FAIRsFAIR workshops
-
RDA 14th Plenary
- Early Career meeting:
Top research for EC:
- think open (to be shared), research outputs (data access / future), encouragement for EC to be open.
- be motivated for open science, think DMP from beginning
- DMPs: oriented to projects, how about long-term data stewardship?
- Discussion about the "burden" of doing/maintaining DMPs during the research: effort for the researcher? how to distribute activities and responsibilities with data stewards? role of researcher vs role of librarian?
My point of view follows the opinion of Barend Mons (GO FAIR), in which the data steward should be involved during the whole lifecycle of a research project, from the proposal to the long-term preservation of data. But to make this feasible, organizations must invest in data stewardship and curation centres, such as the Leiden Digital Competency Center (LDCC) in Leiden University. Funders could enforce that a certain percentage of funding investments (e.g., 5%) should be used for the data management (during the project lifecycle) and long-term data storage/availability. In my opinion, the responsibility of performing data management (as well as software engineering) shouldn’t be on the researchers’ side, rather, the organization should provide professional data stewards to be responsible for data management planning and execution with the support of the researcher. Similarly, when developing research software for reuse, the organization should provide software engineering professionals.
- 23rd (Wednesday):
- Opening session plenary:
- Data center Finland (CSC)
- EC: strengths, weaknesses, role of public sector, European cloud initiative (+EOSC), the priorities of the new commission, ongoing
- evolution of research data sharing: changing paradigms in science, different levels of openness per field (e.g., environmental vs digital humanities)
Session: https://www.rd-alliance.org/curating-fair-and-reproducible-data-and-code
- In order to curate for reproducibility, activities must include a review of the computer code used to produce the analysis to verify that the code is executable and generates results identical to those presented in associated publications. CURE has been implementing practices and developing workflows and tools that support curating for reproducibility.
- Emphasis on machine-actionability: reason to include “code” (software). Focus on computational reproducibility
- Workflow slide: Roles for data and code review (in terms of accepting/storing in library)? What skills are necessary?
- Role of interoperability for usability? Semantic interop. -> common understanding among involved parties
- CISER Workflow all-in-one Reproduction: “run code: error-free” (R-Squared?).
- AI hospitals and research
- 1st presentation:
- Downstream vs upstream: phases of a common scientific workflow
- MIP approach: where the top-level “common agreement” is deployed? Who is responsible (govern model)
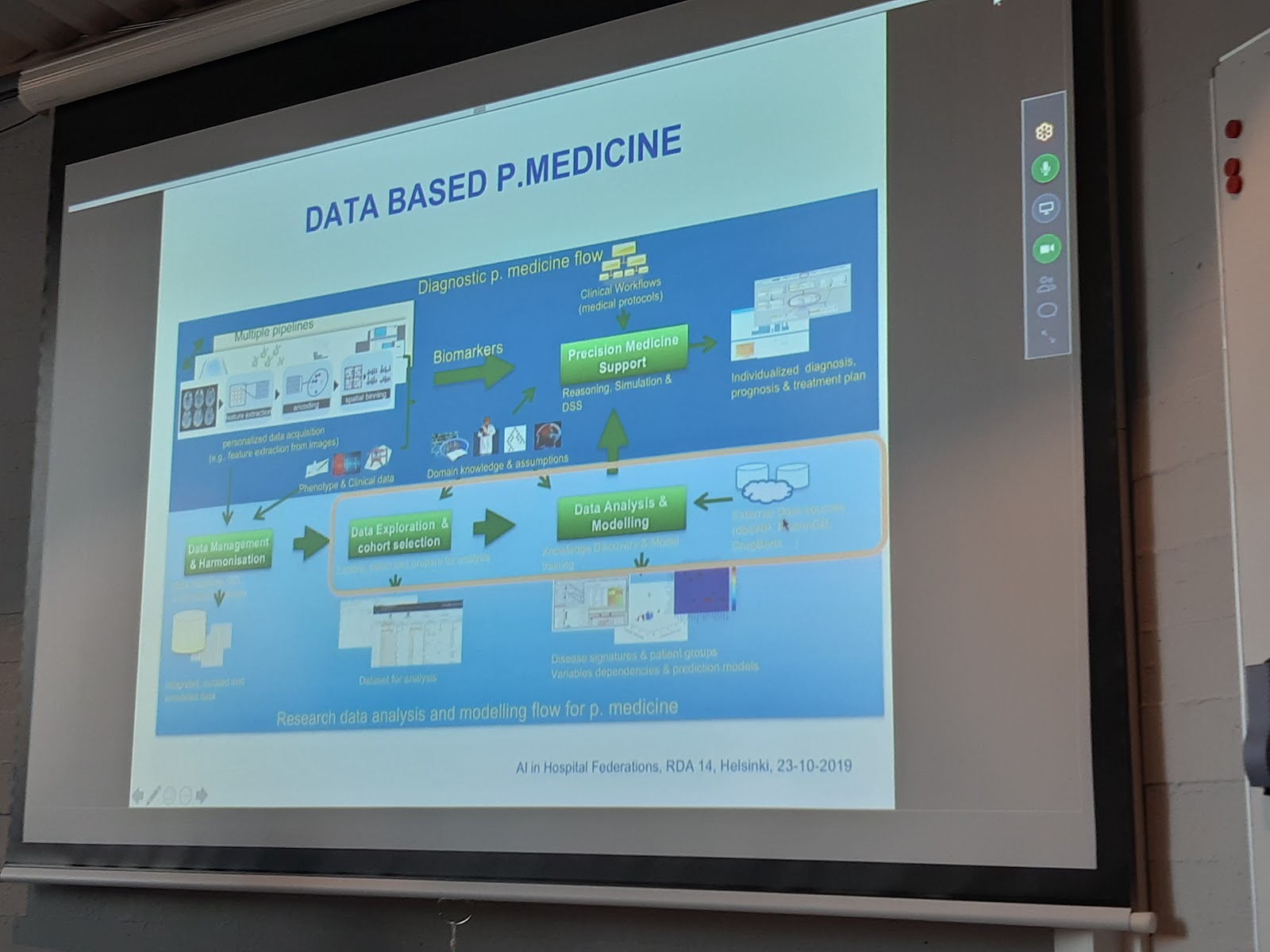
- need better privacy models (anonymization)
- go to “hospital federations”

- 2nd presentation:
- methodological workflow, “responsible reporting”

- measuring reproducibility: framework developed with NLP, ontologies, ML, etc
- NLP: look for goal, hypothesis, methods, etc
- aware of the nanopublications? Overlapping with the FAIR funders study (end lifecycle).
- Reproducible health data workflows: build a “metadata standard” (CWL + EDAM, W3C MLSchema, PROV for Workflows?) - CEDAR
- how to standardize protocols? (https://www.myexperiment.org/home https://www.protocols.io/)
- Session: Mgmnt notebooks
https://www.rd-alliance.org/management-computational-notebooks
- FAIR objects topic:
https://docs.google.com/document/d/1w36NYWnP90rHZNDZI9fqIBLx2-MiLDIwBCM224T3Itg/edit
- 24th (Thursday):
- Plenary (24th)
- Discussion about if open data and open science is an utoppy: no. So, how long it will take to make it happen? For some panelists it will take long, such as the Internet (1st launched in 1969, so 50 years now). For some panelists it will take much less. It is common sense that the technologies are there (e.g., hardware), we can store and retrieve huge amounts of data with the current infrastructure. The main issues are related to the social/cultural and institutional challenges, e.g., for sharing data.
- Threats to the discussions: (1) issues on data quality and sharing. (2) “data as dust”: metaphor more appropriated “data as water”.
- “data owner” issue: who should own? Concept of property.
- 25th (Friday):
A “peaceful” discussion regarding the paper on FAIRness of DMP templates, moment when Luis and Patricia achieve common understanding:

- Session: https://www.rd-alliance.org/access-human-data-makes-difference
- Personal health train project (Zin): https://www.youtube.com/watch?v=Sn-KK4reRGg
- FAIR data trains:


- VU Amsterdam is participating.
- “distributed analysis”
- “farm data train”: other initiatives in Germany and Switzerland
- FAIR for sensitive data (LO): focus on A
- discussion on synthetic data
