Complex Citations Working Group Case Statement
Background and history:
During a Town Hall at the AGU Fall Meeting in December 2020 the challenge of complex data citations was identified as an urgent concern within the Earth, space, and environmental sciences.
This working group addresses the use case of citing a large number of existing objects (e.g., datasets, software, or physical samples) in a way that allows credit for individual objects to be properly assigned. Such collections of objects may contain hundreds to millions+ of elements, and the ‘complex’ citation might need to encompass subsets of elements from multiple collections. The intention is for the recommendation to be broadly applicable within and beyond the Earth, space, and environmental sciences.
The working term “reliquary” is used to refer to this concept throughout this document. However, there exist a number of alternative terms including Data Collection, Package, Crate and more. Infrastructure and guidance are still required to make it easier for researchers to use this type of citation and to receive or give credit for the object used in the research. Solving the problem of these reliquary citations is critical to enabling reproducible research. Moreover, enabling these complex reliquary citations will be important for researchers to be able to trace citation and usage of their work and report on its impact to funders. For policy makers, it will allow the effects of policy decisions to be accurately tracked through citation and analysis of the supporting data.
In this Working Group we want to expand on the work that happened during 2021, when a tenacious group of researchers, repositories managers, infrastructure experts, journal staff, and indexers worked to define the problem, with a focus on scoping the considerations to using data collection citations and enabling credit to data creators. This group conceived of a basic approach that applies to most situations and has begun drafting recommendations. Now, we want to engage with the broad RDA community to fully develop the recommendations, identify adopters, and work on promoting these recommendations to adopters for endorsement.
We are especially interested in inviting those with an interest in PIDs (e.g., Digital Object Identifier - DOI), FAIR Digital Objects, and DOI collections, such as repositories creating DOI collections and journals supporting citing aggregations of PIDs, as well as funders and others with an interest in enabling and tracking credit for the elements of a DOI collection.
Charter
This charter will provide a concise articulation of what issues the WG will address within a 18-month time frame and what its “deliverables” or outcomes (including a Recommendation) will be.
A method is needed for handling citation of large numbers of objects, particularly datasets, software, and physical samples, in scholarly work. The method should allow the citations of the objects to be counted as primary citations (as if they were cited individually in the reference section) in the scholarly work. The solution should also enable aggregators of large numbers of datasets to publish ‘object collections’ that can be cited together in the reference section of a scholarly work without losing the primary citation credit and the ability to track credit for the underlying object contributions. The need for this method arises from a common use case, in which an author collects large numbers (e.g., 50 to millions+) of existing objects (e.g., datasets, software, or physical samples), or subsets of objects. Each object has its own creators, repositories, funders and persistent identifiers, but collectively the objects are used together in a single analysis (Agarwal 2021).
In this use case, the object authors are not interested in being collected into a single larger collection (or new dataset) with a single identifier.
Problem:
-
Authors need to cite papers, software, physical samples, and datasets in their papers. They are not always able to fit all the required citations in the reference section and thus end up citing many of them in the supplementary material. These references in supplementary materials are not currently counted as primary citations. They also do not print with the paper. In the case of high-volume data in a data collection, the authors may want to add more detailed information about each dataset element to make their study reproducible.
-
A project or data system that is reusing large numbers of existing datasets, which may be collectively part of a single analysis, must include citation of the collection of datasets without violating the data usage policy requiring primary citation credit to the individual datasets used.
-
The persistent identifiers on the objects in the collection need to be interpretable even if the original repository no longer exists.
-
The citations of hierarchical research objects with persistent identifiers at multiple levels in the hierarchy where underlying elements need to be tracked over 2 or more levels of the hierarchy.
Specific Outcomes:
-
A recommendation for the best practice in creating a collection/package of digital objects that are hosted by one or more data centers/repositories.
-
Research infrastructure that enables credit to be acknowledged for each individual element of a collection/package of digital objects.
-
Journal guidance that supports authors using a collection/package that enables citation of each individual digital object.
-
Indexer guidance that provides guidance for proper credit and attribution.
Value Proposition
This group will bring together key stakeholders to build on earlier work and establish a common understanding of citation needs for a collection or ‘package’ of digital objects.
We include here selected use cases to describe the broad application of the work.
Use Cases:
We have three well developed and documented use cases (see Appendix for detailed descriptions):
-
Large Collaborative Earth Science Projects (LCESP): A large number of datasets from different projects and providers is analyzed for a publication. The number of citations is too high for a reference list.
-
British Oceanographic Data Centre (BODC): Citable datasets belong to several data collections or data products. Users select their individual selection of datasets for their studies, which need to be cited unambiguously.
-
International Panel on Climate Change (IPCC): IPCC reports utilize model data of Coupled Model Intercomparison Project (CMIP), which provides citable data collections composed of datasets identifiable by Handles. IPCC authors analyze few datasets across several CMIP data collections together with datasets from other projects and providers to create report figures and other key results. These input datasets need to be cited unambiguously.
We know of other emerging use cases including:
-
Ground Geophysical Surveys (2030 Geophysics Project) when a set of instruments are deployed at a series of instruments either on a grid or on a ground survey (e.g., seismology, GNSS, magnetotellurics). Each individual site can be identified, and then a group of instruments combined in a survey to form a permanent or a temporary network the collector of the data, the instrument, the funder and the processor of the data can be a different entity. Hence there is a requirement to have a way of aggregating data from multiple sites into various combinations, but still be able to recognise the funder, collector, instrument etc that is unique to each site.
-
Physical Samples (RDA Physical Samples and Collections in the Research Data Ecosystem IG) Physical samples can be collected from multiple sites and multiple sampling campaigns: each site can have a different collector and funder, and they can be stored in multiple repositories. Multiple collections can be made from each collection and hence there is a need to be able to apply a single identifier to the aggregated collection as this is unique, as well be able to cite the identifiers of each individual sample within a collection. Theoretically, an individual sample can be part of multiple collections.
-
The CODATA OneGeochemistry Working Group. In geochemistry it is common practice to collect a set of samples, analyse each using multiple techniques and publish all data for multiple samples as a single dataset. This aggregated dataset then has a single citation related to an individual report/scholarly publication. The dataset is given a globally unique, resolvable Digital Object Identifier (DOI), thus facilitating transparency and reproducibility of the data and conclusions of that publication. However, increasingly, the same individual sample and analytical results can be reused in multiple other datasets and research publications. On publication, each subsequent dataset is then assigned a different DOI. Further, once published a dataset can be integrated into multiple compilations by other researchers and each resultant dataset in turn, is also given a different DOI.
-
From DataCite: Some data repositories register DOIs for individual files and want to relate these to the dataset. While is possible to add IsPartOf/HasPart relationships using RelatedIdentifiers, many of the same challenges apply here. The recommendation should account for multiple levels of hierarchy, or collections within collections.
Primary adopters will include:
-
Repository managers: repository policy, guidelines and education
-
Journal publishers: journal policy, author guidelines, author education
-
Infrastructure: Common processes for handling collection/package citations that enable credit.
-
Indexers: Common processes for handling collection/package citations that enable credit.
-
Funders: Common expectation that digital objects will be cited and that a collection/package is a recommended means to enable attribution and credit for the individual objects.
Engagement with Existing Work
We are inviting those with interest and expertise in Persistent Identifiers, FAIR Digital Objects, DOI Collections, repositories creating DOI Collections, journals supporting citing DOI Collections, and organizations that support infrastructure that enables credit for the elements of a DOI Collection to participate in the Working Group.
We will collaborate with the Working Groups related to the ESIP/RDA Earth, Space, and Environmental Sciences IG, with RDA/WDS Scholarly Link Exchange (Scholix) WG on infrastructure issues, and with the Data Citation WG on best practices in citation. The work of the Complex Citation WG is also related to the concepts discussed in FAIR Digital Object Fabric IG, the Data Granularity WG, and the Global Open Research Commons IG and the output of the historical RDA/WDS Publishing Data Workflows WG.
Additionally, we will invite participation from those in the publishing community working on citation challenges.
We understand that this work is applicable beyond the Earth, space, and environmental sciences, and will promote that aspect to our colleagues.
Work Plan:
The final recommendation of the working group will be a document outlining:
-
A recommendation for creating a collection/package of digital objects.
-
Research infrastructure that enables credit for the elements of a collection/package of digital objects.
-
Journal guidance that supports citation of digital objects in a collection/package.
We will also develop examples demonstrating the recommendations in practice that will be generated by the participants to illustrate the feasibility of the recommendation.
The working group will start by reviewing work already underway to develop use cases and identify the needed properties and opportunity. The focus of the working group will be to review and expand the use cases as needed, to develop the recommendations, and to provide prototypes and support adoption.
Timeline:
-
Months 1-6: Develop the current use cases and create a prototype for demonstration, review and consideration.
-
Months 6-9: Create a set of recommendations.
-
Months 9 - 12: Implement one or more prototypes.
-
Months 12-18: Support adoption and additional implementation.
The working group will utilize a combination of monthly online meetings, RDA ESES IG Plenary sessions, and ad hoc meetings as needed. Asynchronous contributions to online documents will allow the group to make additional progress outside of meetings. Meeting reports and running minutes will be organized by chairs and shared with team members. Working Group progress will be shared at RDA Plenaries
Consensus within the WG will be achieved through facilitated discussion during monthly meetings and through email discussions. Conflicts encountered that cannot be resolved through facilitated discussion will be adjudicated by the Co-chairs, who have had extensive experience in managing and leading volunteer groups to consensus. WG milestones are tangible outputs by which the Co-chairs will gauge progress and ensure adherence to scope. Specific goals and agendas will be developed for each meeting with the timeline in mind and to keep the working group on track to complete the task in a timely manner.
Engaging the relevant data publication stakeholders to build consensus on a path forward is intrinsically tied to a shared understanding of these individual groups’ needs and challenges. Much ground work has been laid by the ESES IG to engage these stakeholders through previous meetings and opportunities to share use cases and promote discussion. The WG will continue this practice through RDA Plenaries and monthly meetings.
Adoption Plan:
The initial work by the Data Citation Community of Practice established the value of the defined outcomes for researchers, journals, and scientific repositories. The work, outcomes, and recommendation developed by this Working Group will be presented at the annual meetings of societies such as the American Geophysical Union, European Geoscience Union, Japan Geoscience Union; organizations such as Earth Science Information Partners; and publisher societies (e.g., Council for Science Editors, Society for Scholarly Publishers, and STM). During these meetings we will be seeking endorsement and adoption.
We have specific commitment from:
-
Repositories:
-
ESS-Dive
-
British Oceanographic Data Centre
-
International Panel on Climate Change (IPCC)
-
National Computational Infrastructure
-
Zenodo
-
-
Journals/Journal Infrastructure
-
American Geophysical Union / Wiley
-
NISO / JATS4R
-
DataCite
-
CrossRef
-
Schema.org
-
-
Indexers
-
Astrophysics Data System
-
Web of Science
-
The Working Group will adjust and refine as necessary before the completion of the group’s 18 month term.
Appendix
Website documenting previous meetings
https://data.agu.org/DataCitationCoP/
Further description of the Use Cases
- British Oceanographic Data Centre (BODC)
- International Panel on Climate Change (IPCC)
- Large Collaborative Earth Science Projects (LCESP)
British Oceanographic Data Centre (BODC), Justin Buck and James Ayliffe
BODC has earned an international reputation for its expertise in the management of marine data. The BODC repository houses datasets concerning the marine environment. The bulk of the data in BODC is collected on oceanographic cruises. Once the datasets are received, the BODC organizes the data into thematic data products enabling searching and usage of data from across the cruises based on a particular data need such as “current meters” or “ocean level.” The user of these data products will typically utilize a subset of a data product. In order for the user to properly cite the data they used, they need the citations from the original cruise datasets.
Data from studies are submitted by originators and will have a DOI assigned to the data accession (making the data citable in academic literature). There are currently 8000 accessions with data spanning sea level data from the 1800’s to NRT data up to the present day.
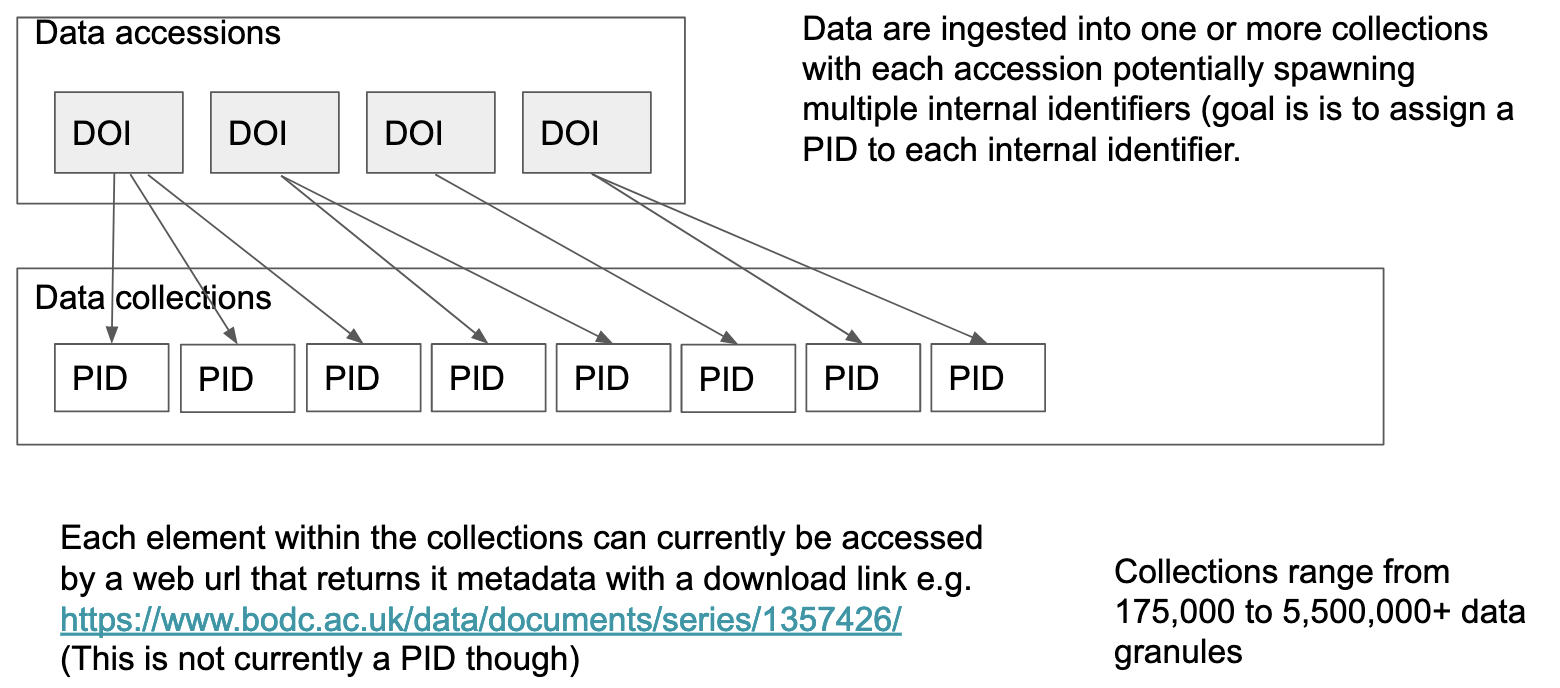
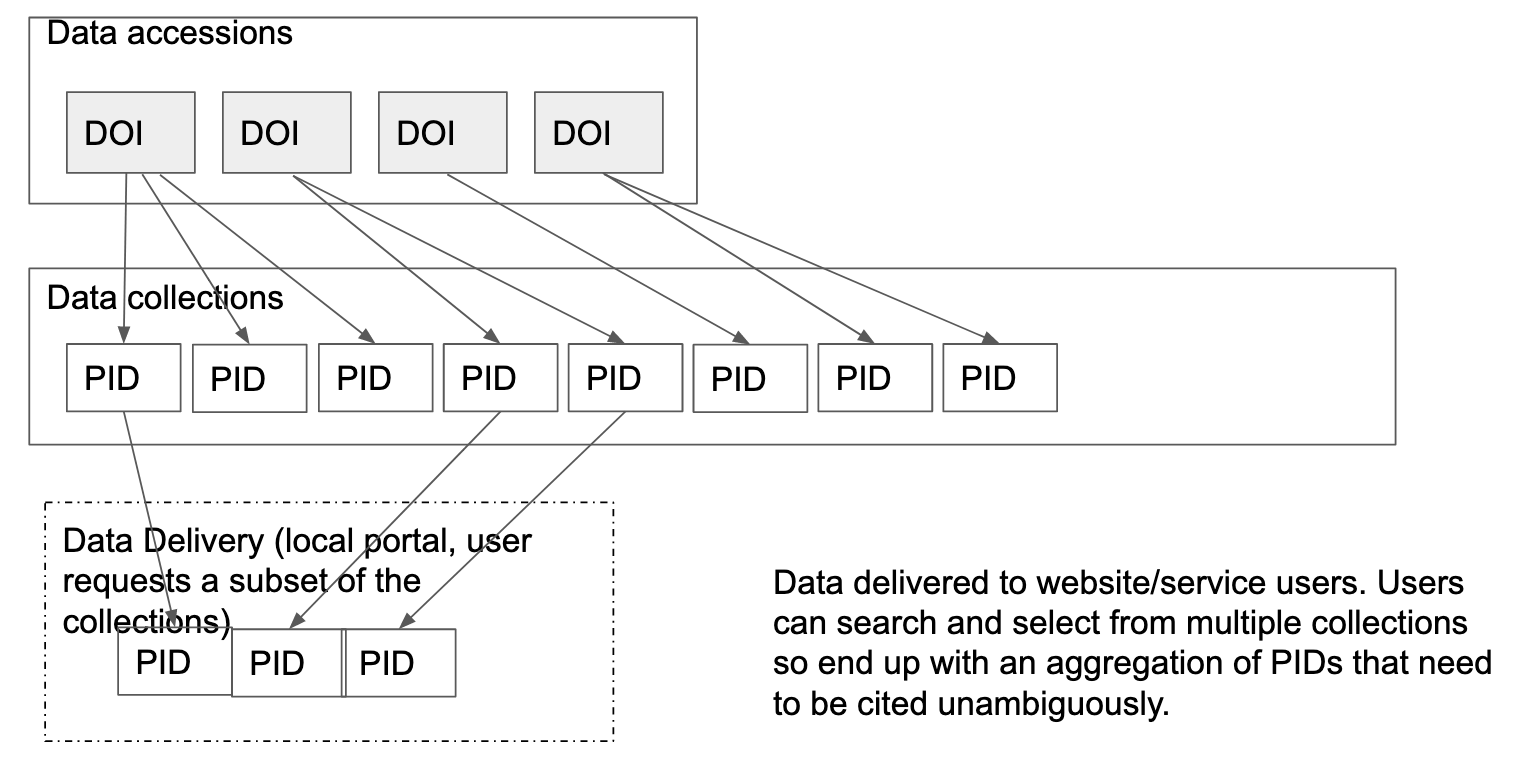
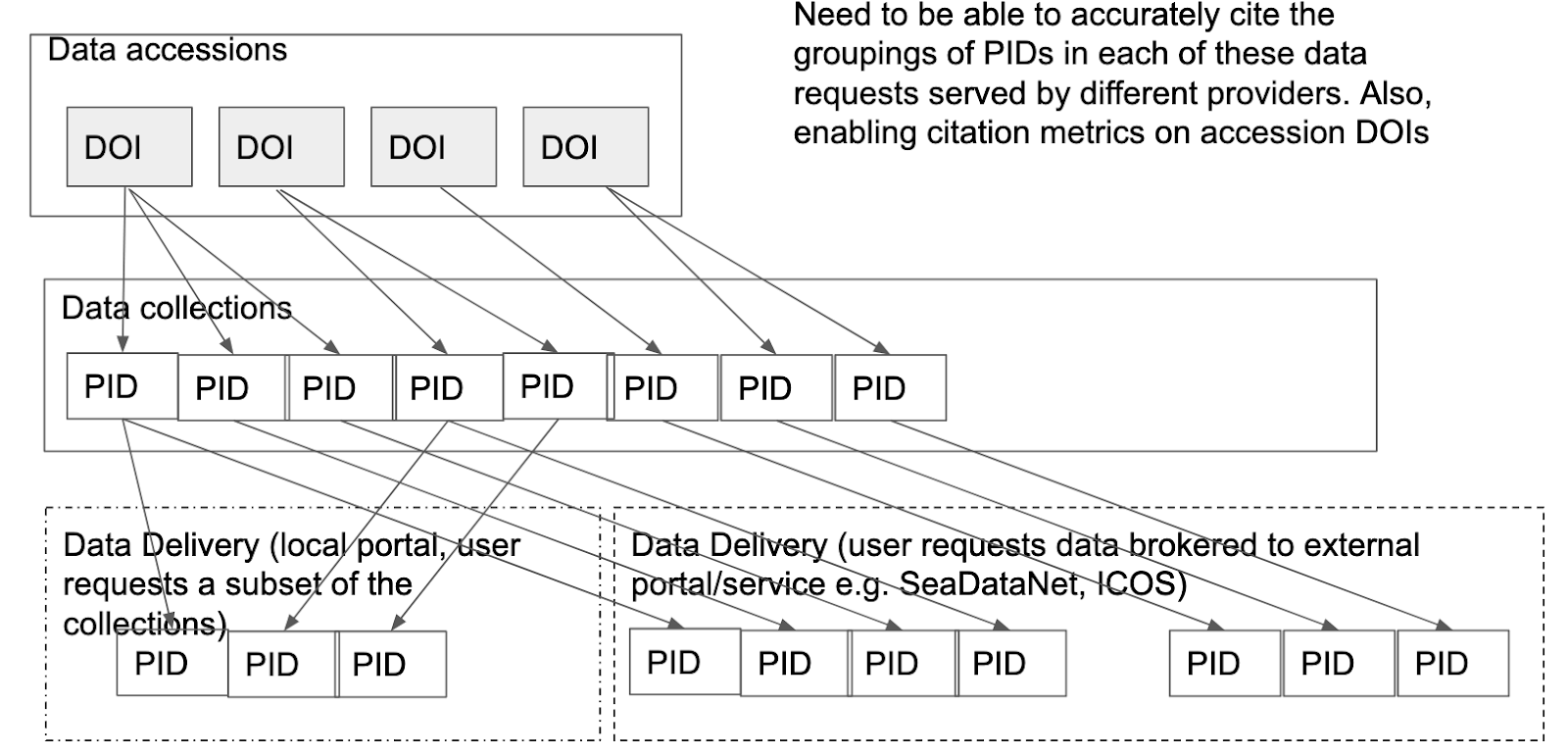
The BODC use case was first raised in the December 2020 AGU fall meeting (Buck, 2020) and has been iterated to the current version as part of the complex data citation working group which is now under for this RDA working group.
International Panel on Climate Change (IPCC) - Martina Stockhause
(https://docs.google.com/presentation/d/1o-hR9kPoIs-Zpk4IwRDBrG2USvWL5lNXx5WOcD5gJxM )
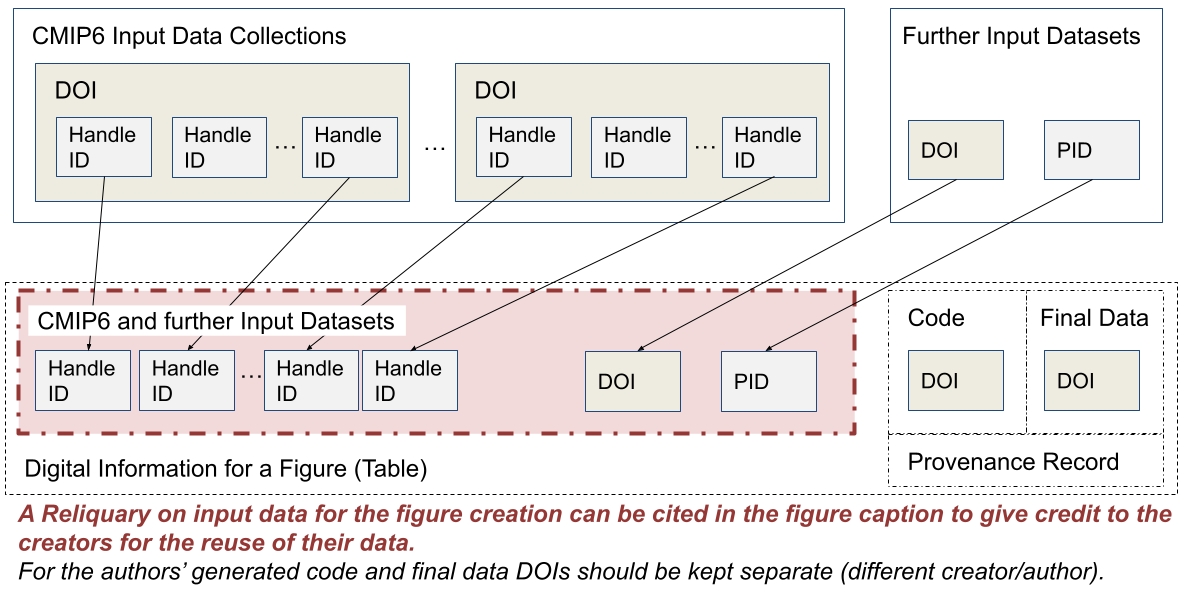
The IPCC assesses the World’s climate regularly based on the latest research in the area of climate change. The results of the Assessment Reports are mainly based on peer-reviewed literature but scientific data is also analyzed, e.g. to create several report figures. The introduction of the IPCC FAIR Guidelines into the current Sixth Assessment Report (AR6) aimed at enhancing the transparency of the AR6 and at enabling the traceability of results and the reproducibility of figures.

IPCC FAIR Guidelines for AR6:
-
FAIR Guidelines Key Points:
-
Reproducibility of figures/tables:
-
Input data usage on dataset granularity is collected for each figure and table in the report.
-
Analysis scripts create final datasets, which are displayed in figures and tables of the report.
-
-
Credit for input data providers:
-
Input data is cited by their DOIs in the report outside of figure caption for length reasons.
-
-
-
Partners / Contributors:
-
IPCC hosts the reports. The registration of crossref DOIs for reports and its chapters is planned.
-
Input data (not already archived) and final data are archived in the IPCC Data Distribution Centre (DDC), which is jointly managed by currently 4 DDC Partners (DOI registration for data).
-
IPCC TSUs (Technical Support Units) gather information from authors and take care that analysis scripts are archived in Zenodo, incl. DOI registration.
-
The Coupled Model Intercomparison Project Phase 6 (CMIP6) provides one of the most important input data for the AR6, with ca. 150 participating numerical models running several experiments. Data contributions are submitted by originators. DOIs are assigned on multiple datasets (model experiments). Datasets are assigned Handle IDs. Handle metadata (will) include the related DOIs. Ca. 2400 DOIs and ca. 5 million Handle IDs are available.
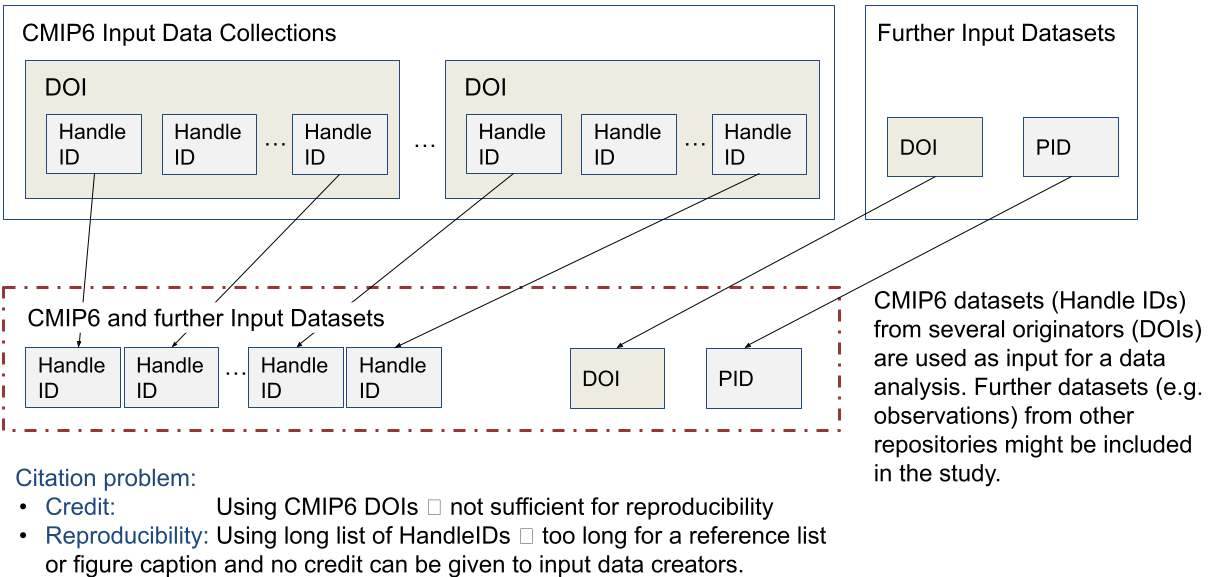
Large Collaborative Earth Science Projects (LCESP) - Deb Agarwal
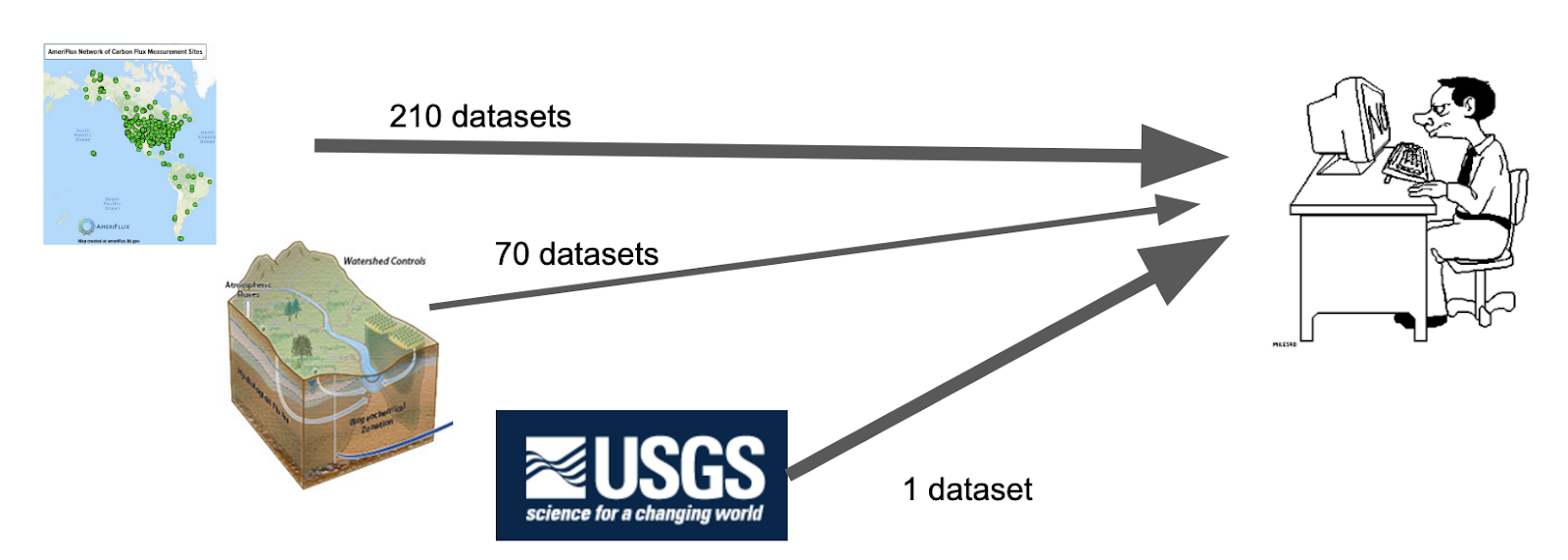
As data becomes more accessible, data consumers are able to incorporate data from many data packages into an analysis. However, when a large number of data packages have been used, properly citing the data in the reference section without going over page limits can be difficult. For example, a paper based on the data from all the AmeriFlux sites, all of the NGEE-Tropics data packages, or all of the WFSFA data packages would need to include 350, 70, and 96 citations, respectively, in the references section. This large number of required citations often leads to the citations for the data being provided in the supplementary materials, within data/metadata files, or as a table of identifiers. In all of these cases, it is difficult to programmatically find the citation of the data and thus is unlikely to be counted in the data's citation metrics.
The Use Case authors developed example reliquaries.
BODC - https://docs.google.com/spreadsheets/d/1IhMNyK0-B8PuMA57HyNRemHz9g9BpSsCoir0xrlJsd0/edit?usp=sharing
IPCC - https://docs.google.com/spreadsheets/d/1sdAiAv3hzk9nNSLt_k0o41QHxF_lfj9QwSKXrHGmdSA
LCESP - https://docs.google.com/spreadsheets/d/10v58s_ZeMlffXy_pxjleK08LEhbVhYOetqh80BzGT_8/edit?usp=sharing
List of possible existing solutions (from 8 June 2021 meeting)
RDA Scalable dynamic data citations - The approach recommended by the RDA Working Group relies on dynamic resolution of a data citation via a time-stamped query also known as dynamic data citation. It is based on time-stamped and versioned source data and time-stamped queries utilized for retrieving the desired dataset at the specific time in the appropriate version. Instead of providing static data exports or textual descriptions of data subsets, we support a dynamic, query centric view of data sets. The proposed solution enables precise identification of the very subset and version of data used, supporting reproducibility of processes, sharing and reuse of data. (Rauber 2015). Hunter and Hsu (2015) implemented this methodology to provide fine level credit to observers contributing to the eBird citizen science data set.
Non-RDA
RO-Crate - RO-Crate, is based around these principles: a) all metadata is Linked Data, using schema.org as much as possible; b) extensible for different domains; c) retain the core Research Object principles Identity, Aggregation, Annotation; d) inferred metadata rather than repetition; e) “just-enough” provenance; f) layered validation; g) archivable with BagIt and other packaging tools and compatible with digital preservation approaches; h) hooks to reuse existing domain formats; i) designed for easy programmatic generation and consumption. Similar to the approach of BioSchemas, rather than building new specifications from scratch, we aim to build best-practice guides and validatable profiles for building rich research data packages with existing standards, without requiring expert knowledge for developing producers and consumers. RO-Crate was developed as a way of gathering and pointing to datasets that are held in different repositories, transcending the scattered repository issue, and being able to exchange between repositories. RO-Crate used Linked Data for its metadata files.
(Sefton 2019, Goble 2021).
Data collections -
NERC EDCs or any other environmental data centre (where DOIs are applied to data as they arrive which are then aggregated up in to harmonised data products/collections , also have the potential for high granularity PIDs within collections leading to a graph of PIDs that will also connect to other external PIDs)
Data papers -
Enhanced publications as a general means to define “dataset in context”
DataCite resourceTypeGeneral in the DataCite metadata schema v4.4 (P48) defines a collection as::
"An aggregation of resources, which may encompass collections of one resourceType as well as those of mixed types. A collection is described as a group; its parts may also be separately described."
Theoretically individual parts could be assigned identifiers using either the RelatedIdentifier or RelatedItem fields. These fields will be retrievable from the DataCite API and would theoretically be traversable on any self-respecting PID graph.
This solution has not been fully tested and even if it works it will only apply to those groups that use DataCite Identifiers.
Supplementary information
Definitions
Landing pages - The internet accessible location that a PID resolves to that provides information about the object and access to the object.
Data repositories - Data repositories who serve collections of data from aggregate data collections containing multiple PIDs will need to serve data to users with RO crates to enable citation of data requested from the repository. Additionally, data repositories will need to serve the PID graphs of holdings (including PIDs, linkages/associations, and the graph/ontology) to PID/DOI citation service to enable metrics/citations of individual PIDs to be determined (methods such as the RDA collections API may facilitate the sharing of the PID graph).
Previous work from this effort
Starting in December 2020 during a Data FAIR Town Hall at AGU’s large meeting we reached out across the community for interest in supporting virtual working sessions that would lead to recommendations, adoption, and a better of citing large numbers of data/digital objects in journal articles and other publications.
During 2021 we held three large working sessions as well as smaller group development efforts.
8 April 2021: Develop a common agreement on the use case (and variations) as well as hear from those whom it affects. Materials and link to recording: Agarwal, Deborah, Coward, Caroline, Stall, Shelley, & Erdmann, Christopher. (2021, April). Data Citation Community of Practice - 8 April 2021 Workshop. Zenodo. http://doi.org/10.5281/zenodo.4673622
8 June 2021:
Presentations from different repository use Cases:
-
RO-Crate, Carole Goble
-
BioStudies, Ugis Sarkans
-
GBIF, Daniel Noesgaard
-
Pangaea, Uwe Schindler
Infrastructure Elements:
-
DOI Collection, Martin Fenner, DataCite
-
Make Data Count, Martin Fenner, DataCite
-
Scholix / OpenAire, Paolo Manghi
Workshop materials and link to recording: Agarwal, Deborah, Goble, Carole, Soiland-Reyes, Stian, Sarkans, Ugis, Noesgaard, Daniel, Schindler, Uwe, Fenner, Martin, Manghi, Paolo, Stall, Shelley, Coward, Caroline, Erdmann, Chris, 2021. Data Citation Community of Practice - 8 June 2021 Workshop. https://doi.org/10.5281/zenodo.4916734
29 October: We leaned into the term “reliquary” as a temporary word for a collection/package of other DOIs, PIDS, or links.
“Reliquary” Use Cases:
-
British Oceanographic Data Centre, Justin Buck and James Ayliffe
-
German Climate Computing Center/IPCC DCC, Martina Stockhause
-
Ameriflux, Deb Agarwal
Workshop materials and link to recording: Stall, Shelley, Buck, Justin, Ayliffe, James, Stockhause, Martina, Agarwal, Deb, Coward, Caroline, & Erdmann, Chris. (2021, October 29). Data Citation Community of Practice - 29 October 2021 Workshop. Zenodo. https://doi.org/10.5281/zenodo.5641236
We are hopeful to bring awareness of this effort to the broad RDA community, and move forward using the RDA structure.
References
(Agarwal 2021) Deborah A. Agarwal, Joan Damerow, Charuleka Varadharajan, Danielle S. Christianson, Gilberto Z. Pastorello, You-Wei Cheah, Lavanya Ramakrishnan, Balancing the needs of consumers and producers for scientific data collections, Ecological Informatics, Volume 62, 2021, 101251, ISSN 1574-9541, https://doi.org/10.1016/j.ecoinf.2021.101251. https://www.sciencedirect...
(Buck 2020) Justin Buck, James Ayliffe, Elizabeth Bradshaw, et al. More Than Just DOIs, How to Pragmatically Make 50 Years of Diverse Data Centre Holdings and Services Citable, The Perspective and Aspirations of the British Oceanographic Data Centre. ESS Open Archive . December 22, 2020.
DOI: 10.1002/essoar.10505542.1
(Sefton 2019) Sefton, Peter, Eoghan Ó. Carragáin, Carole Goble, and Stian Soiland-Reyes. "Introducing RO-Crate: research object data packaging." http://conference.eresearch.edu.au/wp-content/uploads/2019/08/2019-eRese... (Presentation slides and blog post here: http://ptsefton.com/2019/11/05/RO-Crate%20eResearch%20Australasia%202019...)
(Soiland-Reyes 2021) Stian Soiland-Reyes et al (2021): Packaging research artefacts with RO-Crate In preparation https://stain.github.io/ro-crate-paper/
(Goble 2021) Carole Goble, Stian Soiland-Reyes (2021): RO-Crate: A framework for packaging research products into FAIR Research Objects, https://www.slideshare.net/carolegoble/rocrate-a-framework-for-packaging... RDA IG Data Fabric: FAIR Digital Objects 2021-02-25. [Video recording https://www.youtube.com/watch?v=pz-MLdI7GLA]
Hunter J., Hsu CH. (2015) Formal Acknowledgement of Citizen Scientists’ Contributions via Dynamic Data Citations. In: Allen R., Hunter J., Zeng M. (eds) Digital Libraries: Providing Quality Information. ICADL 2015. Lecture Notes in Computer Science, vol 9469. Springer, Cham. https://doi.org/10.1007/978-3-319-27974-9_7
(Rauber 2015) Andreas Rauber; Ari Asmi; Dieter van Uytvanck; Stefan Proell (2015): Data Citation of Evolving Data: Recommendations of the Working Group on Data Citation (WGDC). DOI: 10.15497/RDA00016. https://www.rd-alliance.org/group/data-citation-wg/outcomes/data-citatio...
- Log in to post comments
- 4315 reads
Author: Bruce Wilson
Date: 16 Dec, 2022
As the ORNL DAAC Manager, I concur in the value of this work. There are multiple other Earth Science use cases that I am aware of, but the use cases outlined here are sufficient to generally cover the range of needs that I am aware of.
Author: Shelley Stall
Date: 07 Jan, 2023
Bruce, thank you for your support and encouragement.
Shelley
Author: Shelley Stall
Date: 07 Jan, 2023
Bruce, thank you for your support and encouragement.
Shelley
Author: Edwin Henneken
Date: 19 Dec, 2022
Looking at our experience with the Asclepias project, capturing and attributing software citations, I think that the final recommendation of the working group should also include guidance for indexers. For us (the Astrophysics Data System) it is important that metadata registered with digital object DOIs meets certain requirements, but it is also important to know how we should generate e.g. BibTeX for digital objects indexed in our system. We have seen how fast "bad" BibTeX can permeate the world of publications. The DataCite metadata schema allows for various contributorType values; what will be the expectation of the community for indexers to do? Keep the distinction? In the case of digital objects in the fields of astronomy, planetary science and heliophysics, we strongly recommend the use of keywords, taken from the Unified Astronomy Thesaurus. In general it will be good practice to have keywords come from controlled dictionaries; this will help greatly with discovery. The ADS is looking forward to participating in this valuable and crucial discussion!
Author: Shelley Stall
Date: 07 Jan, 2023
Ed, thank you for your comment and encouragement.
I will update the charter to include guidance for indexers.
Shelley
Author: Kelly Stathis
Date: 20 Dec, 2022
Very glad to see this case statement. From DataCite's perspective, I hope this work can inform how the DataCite metadata schema evolves to handle collections of objects. The emerging use cases for instruments and samples are of particular interest to us.
A related use case: some data repositories register DOIs for individual files and want to relate these to the dataset. While is possible to add IsPartOf/HasPart relationships using RelatedIdentifiers, many of the same challenges with the "reliquary" use cases also apply here. It would be good for the recommended solutions to account for multiple levels of hierarchy, or collections within collections.
Author: Shelley Stall
Date: 07 Jan, 2023
Kelly, thank you for your comment, suggestions, and encouragement.
We will be sure to invite the Instrument PID WG to participate.
I will also add your use case and the need to account for multiple levels of hierarchy. or collections within collections.
Shelley
Author: Elisha Wood-Charlson
Date: 27 Dec, 2022
This is a very valuable effort, and I agree that the provided case studies are sufficient for the design stages. Representing a complex but biological data focused platform that also interfaces with samples, publishers, and DataCite, I would be happy to evaluate the recommendations for relevance and feasibilty, as they are developed.
Author: Shelley Stall
Date: 07 Jan, 2023
Elisha, thank you for your support and encouragement. It would be great to get your feedback on the recommendations.
Shelley
Author: Justin Buck
Date: 28 Dec, 2022
Hi Shelly & Deb,
Thank you for pulling all this material together to form a really coherent case statement.
Attached is a commented version with minor edits and an initial reference for the inception of the BODC use case. I think we may also need to raise the needs to track citations across more than 2 levels of the PID graph too, it may be too much detail for this stage of the process though.
We are looking forward to continuing to develop this as the group evolves.
Warm regards,
Justin
Author: Shelley Stall
Date: 07 Jan, 2023
Justin, thank you for the updates. I will incorporate these.
Best regards, Shelley