Persistent Data Identification: The Decentralised Future
Authors/Contributors:
- Andrey Vukolov, Elettra Sincrotrone Trieste
- Erik van Winkle, DeSci Foundation
- Christopher Hill, DeSci Foundation
Ensuring persistence on the internet is a complex challenge. The half-life of a URL has been widely documented to be approximately 10 years. Persistent identifiers (PID) aim to solve this problem using a series of social and technical mechanisms to guarantee consistent mapping and resolution to a target resource. Regardless of what participants come and go in a network (publishers, technology platforms, data storage providers and identity authorities), PIDs remain.
FDO Requirement Guidelines and FAIR Guiding Principles encourage the assignment of PIDs to any digital object, scientific research outcome, resource or entity that is intended to be preserved, openly accessible, referenced, or published. As it is written in ExPaNDS Deliverable 2.5:
PIDs are not only for documents and data. They can also be used to reference other entities or agents, including people contributing to the research, software, research organizations, physical objects such as samples and instruments, and even abstract concepts such as terms in a controlled vocabulary. As a general rule, whenever something needs to be referenced in a reliable and lasting manner, a persistent identifier should be used.
In the upcoming world of FAIR science, every file will need a PID with fast resolution. An average research project produces a far larger number of research artifacts (e.g. code, data, reviews, sensemaking) than what is currently captured by existing PID systems, and this number is constantly growing. A global endeavor can make trillions of individual research artifacts. As such, trillions of PIDs may need to be minted over the next decade in order to achieve a truly machine-actionable scientific record.
Careful deliberation is put into the system design underpinning a persistent identifier. Architectures along the continuum of centralized to decentralized correlate (even causate) unique combinations of social and technical mechanisms which come with distinct trade-offs, tailored for a given use case. Throughout this post, we will examine a select number of PID architectures, and then detail the challenges arising from their social and technical persistence mechanisms. The post will conclude by examining the dPID system and detailing how decentralized web architectures lead to a PID system comprised of primarily technical mechanisms.
Social contracts under the centralized and federated PID architectures
Most known and popular PID systems implemented worldwide fall between centralized and federated architectures.
Centralized PID systems primarily utilize social mechanisms to guarantee internally maintained persistence. Under centralized architectures, the technical persistence of a PID is often dependent on the social persistence mechanisms. Central authorities such as ORCID and ROR have proven trustworthy over time, leading to efficient implementation and administration schemas (fig. 1) at scales of ~1-10M. Given that academia will likely never have billions of individual researchers or research organizations, centralized architectures managed by trusted central authorities are simple, efficient, and can be considered fit-to-purpose.
An example of a mix between centralized and federated architecture can be seen in DOI. DOI starts with a non-profit organization residing on top of a system of PID Registrars. Each registrar manages the underlying system of centralized prefix-based lookup tables with federated URL redirection, functioning as independent registries with independent databases replicated at the discretion of the centralized authority. Each independent registration authority maintains its own provenance authority of its own and ensures the persistence of associated PIDs. The non-profit dedicates resources across the federation of infrastructure providers to maintain persistent registry infrastructure. Through this structure, DOI aims to preserve the administrative efficiency of centralized approaches while achieving the redundancy and distributed curation of decentralized approaches.
However, as the central PID infrastructure governance and funding mechanisms are centralized, the non-profit is ultimately obliged to preserve the single-layered central registry of all the records minted for all time. As with centralized PID systems, DOIs are fit-to-purpose for manuscripts. While the system has worked well for manuscripts, the technical limits of DOI’s federated architecture are being approached as the system closes in on 1B PIDs. The responsibility of maintenance for correct URL mappings is passed to platform operators, causing complexity and growing technical debt around link rot and artifact fragmentation without innate verifiability for content drift.
One of the best scoping investigations on the possible implementation of a fully federated approach was performed and published by the FREYA project. From this investigation, a problem was deducted. Underlying social contracts led to increasing expenses around the maintenance of webs of trust inside the community. These expenses grew factorially given the factorial increase in the number of network connections required every time a new member was added to the federated infrastructure.
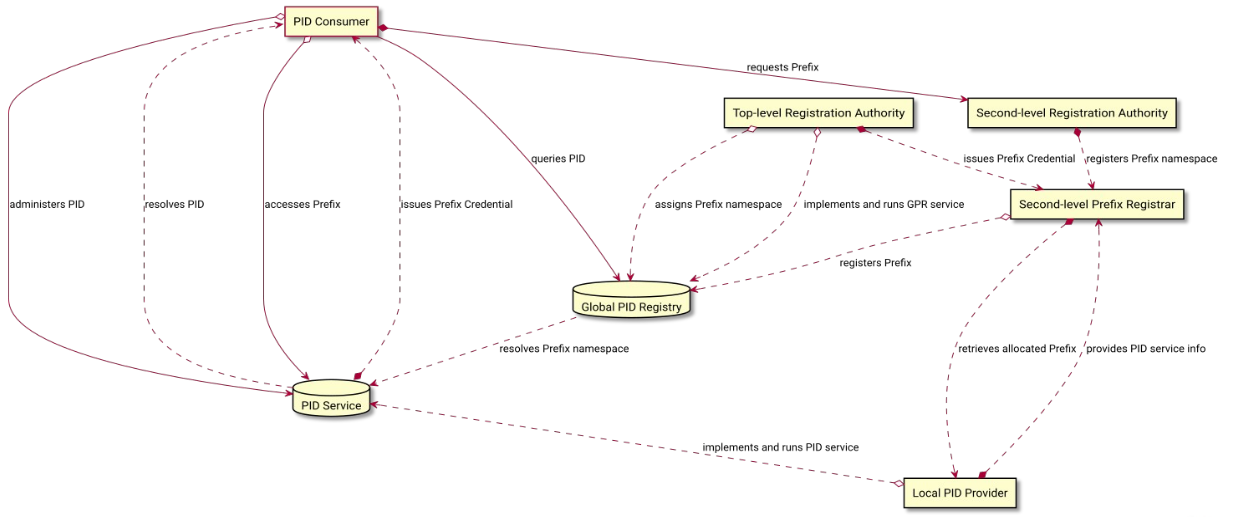
Figure 1. Traditional PID Administration and Implementation Schema
As mentioned above, trillions of PIDs may need to be minted over the next decade for the scientific record to become machine-actionable. While centralized architectures excel in small to medium-sized volumes, they were never intended to scale into the trillions of records. Thus, centralized infrastructures have the potential to become a singular monolithic point of failure. The DOI system has experienced the largest scaling requirements of any academic PID system, closing in on ~1B PIDs minted. Due to the increasing complexity of maintenance over constantly growing amounts of minted PIDs, the growing issues of link-rot, content drift, and inconsistent resolution is becoming a topic of conversation.
Closed PID generation and verification schema compound the traditional “single point of failure” conundrum experienced with centralized architectures, leading to fragility. This aspect of the PID generation schema's closedness is described in the ExPaNDS project's dedicated presentation. Centralized PID governance authorities being the only provenance holder of the underlying record, metadata, and addressed data adds yet another layer of issues. As such, we may fall into a self-assignment trap. The authority tracking all the minted PIDs experiences both exponential expenditure growth and decreasing trust from stakeholders. This self-assignment trap magnifies when record tracking lags behind the growing number of maintained records. These new challenges surrounding PID management expand past academia, to all digital communities in need of persistence at scale. Many communities have turned to decentralized architectures as potential solutions.
Decentralization: Maintaining Persistence through Primarily Technical Mechanisms
Production-grade decentralized systems are architectured to build credible neutrality and eliminate the need for social mechanisms to establish trust between participants. This leads to scalable system designs where mechanisms are primarily technical in nature.
Over the past two decades, a series of open-source communities have arisen, aiming to use decentralized architectures to address the root issues underpinning a lack of persistence on the internet. The core idea behind their proposed technologies is that we should ask a fundamentally different question when resolving online content. Instead of asking a single server "What is the content stored at this location?", we should be asking a whole network “Can you tell me where the content with this fingerprint lives?”. This approach is one of the natural continuations of an idea of the PID Graph, proposing that technical mechanisms can be used as the primary mode of guaranteeing persistence, replacing the social mechanisms used in current systems. In a decentralized PID system, the social persistence of a PID is as strong as the technical prevalence of the voluntarily run network nodes, providing self-describing addressing, data redundancy and sharing with strong consistency. One of the possible workflow schemas implementing the decentralized approach is presented in Fig. 2.
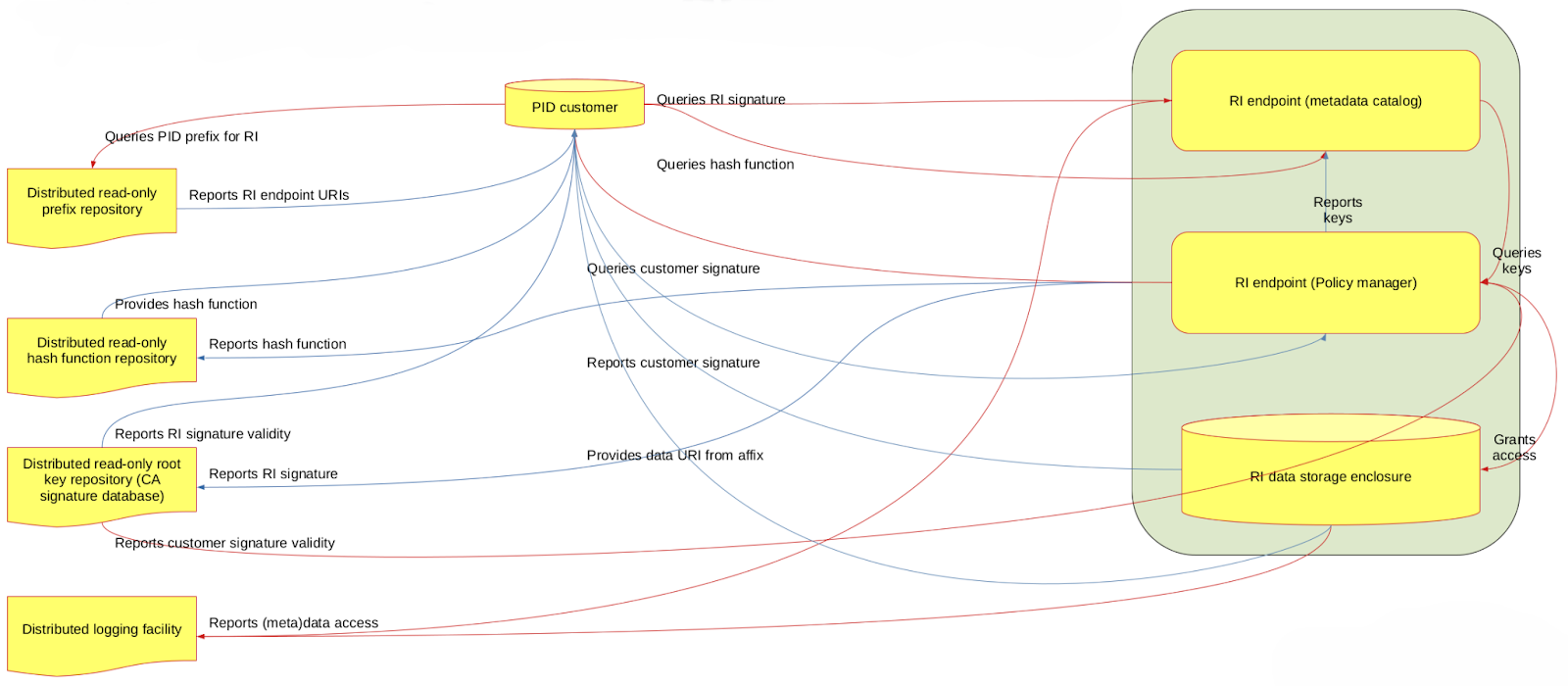
Figure 2. One of the Possible Decentralised PID Workflow Implementation Schemas
The idea described above outlines a potential new model of persistent identification where every participant of the open-state data network provides both data availability/redundancy and dedicated PID namespace-based storage capacity for other participants without needing to establish social trust. In such a system no participant or a group of participants could be considered as privileged/discriminated over the given data or metadata in their access or ability to perform CRUD operations. It provides privacy, sovereignty, data integrity and secure provenance for both data, metadata and timestamps. In a decentralized environment (similar to the W3C DID infrastructure concept) every participant shares the same models, algorithms, and software while owning the cryptographic keys needed to maintain sovereignty over the data they want to identify and share.
Decentralized systems apply a requirement on the participants to reveal themselves and to use digital signature mechanisms to prove their identities. Over time, publicly signed actions in trustless systems lead to identity and reputation provenance, with the presence of data integrity and ownership provenance.
In FAIR Science, several different PID systems need to maintain a level of interoperability. While there is the PID Graph Initiative, the absence of client-side reproducibility of the most existing PID models allows the only approach to obtain the desired cross-resolution and interoperability: third-party side aggregation. The existing decentralized data storage/exchange systems introduce this feature allowing true interoperability and reverse lookup via hash functions, distributed hash trees, and other underlying technologies. While third-party side aggregation is also possible in decentralized systems, decentralization should be named as the most obvious and straightforward way to maintain reproducibility and interoperability between the PID systems, providing unified infrastructure for cross-resolution. This aspect seems especially important because it eliminates the necessity to use and maintain singular interoperability points with specialized dedicated software and computational infrastructure. Thus digging deeper into the granularity of the persistent identification models, it could be said that decentralization does not make PIDs more fragile, but it has huge potential to ensure the persistence of the links between data, metadata bindings and especially, resolution services.
How Decentralized PID could be Implemented: Proof of Concept and Technical Proposal
Thanks to the maturity of the underlying tech stack, dPIDs already exist as a working proof of concept. The dPID project described below is already in beta, receiving development support from DeSci Labs and governance support from the DeSci Foundation. The Decentralised PID Initiative Group (authors of this post) provide both technical and dissemination support for the POC. Building decentralized PID systems with tools specifically architected to address the key problems of persistence on the Internet, can be seen as a preliminary implementation of the vision of FAIR Science and a machine-actionable scientific record in the modern world. dPID considers the scientific data as a versionable file system(a.k.a research objects) stored in the distributed database and addressed by the dedicated persistent identifier via hash-based algorithms. As described in some previous works, dPID uses a content-addressable network to achieve deterministic resolution of IPFS internal Content IDs (CIDs) to their mapped content. As mentioned in the ExPaNDS Project above, content could represent the data, metadata, databases, code files and more. They additionally provide a vehicle for human-friendly URLs, persistent metadata linkages, the addition of typing-based information onto IPFS-based CIDs, and more.
dPIDs use the following technologies:
-
IPFS is the data representation and data networking layer. It creates CIDs (content-identifiers) mapping Merkle-DAGs indexed in a distributed hash table. The Content identifiers (CIDs) they contain are used to identify and resolve PID string representations to the data. IPFS forms a decentralized storage network of content-addressed information allowing resolution, location, retrieval and reproducibility for everyone with the given data. Content Identifiers in the IPFS network are inherently immune to content drift and drastically mitigate the effects of link rot by enabling network participants to mirror copies of the data.
-
IPLD is the data model of IPFS, which represents data objects as Merkle-DAGs. These connected data objects can be used to represent persistent file systems. IPLD ensures that the connections between the nodes in the graph are verifiable and traversable in a deterministic fashion.
-
Blockchain creates persistent recording. A blockchain acts as a distributed ledger with growing lists of records (blocks) that are securely linked together via cryptographic hashes. Smart contracts associated with Turing-complete blockchains allow us to autonomously register the root hash of an IPLD data structure. Through blockchain, records are kept in a highly persistent, secure and decentralized fashion with added redundancy and validity provenance, replacing the social contracts of the centralized systems.
-
Decentralized identifiers (DIDs) are a new type of identifier that enables verifiable, decentralized digital identity. A DID refers to any subject (e.g., a person, organization, thing, data model, abstract entity, etc.) as determined by the controller of the DID. In contrast to typical, federated identifiers, DIDs have been designed so that they may be decoupled from centralized registries, identity providers, and certificate authorities.
-
Sidetree. Sidetree is a protocol implementing scalable W3C Decentralized Identifier networks that can run on top of any existing addressing system (including blockchain-based distributed ledgers) and be as open, public, and permissionless as the underlying addressing models they utilize. This protocol allows users to create globally unique, user-controlled identifiers and manage their associated private key infrastructure (PKI) metadata, all ideally without the need for existing social contracts. In other words, Sidetree solves the inherent throughput limitation of blockchains by bundling multiple write operations in a single transaction.
Persistence in an identifier system can be broken down into components as seen in this PID Forum Discussion. It should be noted that persistent identifiers imply the persistence of data. While guaranteeing the persistence of data is impossible due to cost alone, the replication of data across a wider network helps facilitate increased persistence. dPID functionally implements the level of persistence maintained in the current data persistence state of IPFS, as discussed in the ExPaNDS presentation. The following table illustrates the levels of persistence for the data stored in the IPFS directly (without added persistence features from dPID) following the CID state declared in the DAG. As defined by IPFS Documentation, the pinned state means that a given CID is explicitly declared stored and network-wise provided by at least one peer.
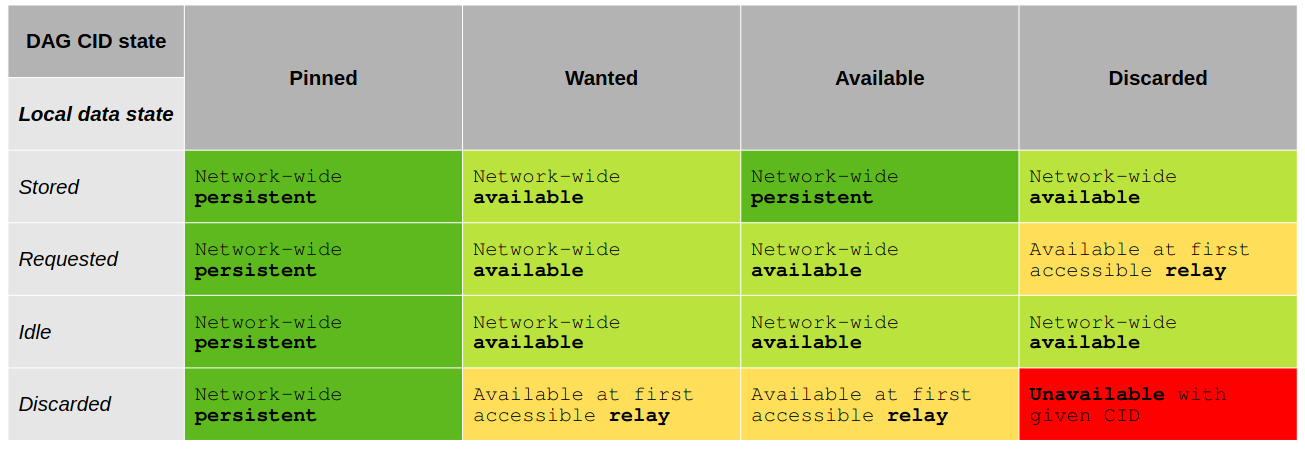
The dPID technology adds to this basis of persistence by providing both high throughput and strong consistency across a decentralized network, out-of-the-box decentralized indexing functionality, human-friendly URLs and more. The persistence of the Requested data to the Pinned level in the context of PID-addressed records means immunity to content drift and built-in redundancy maintaining automatic persistence of the record metadata over the whole network. Through this, the social contract enforcement between the PID authority and the user is replaced by the technical agreement to share the same openly distributed, verifiable and reproducible algorithms, protocols and software, with announced compliance with FAIR Guidelines and FDO Requirement Specifications. The project was presented by one of its inventors, Erik van Winkle who also is one of the leading members of the Decentralised PID Initiative Group, at the International Data Week 2023 in Salzburg. The video of the presentation is openly accessible on Vimeo.
231025_557_The FAIR hourglass: A framework for the practical implementation of FAIR data and services.mp4 from CODATA on Vimeo.
The dPID project and Decentralised PID Initiative Group are striving to provide a user-friendly, open-source, programmable and API-ready decentralized solution. The scalability of dPIDs allows for more granular and interactive means of data curation, by which institutions can attest to the credibility of information. By building on dPIDs, tooling providers can more easily comply with the FAIR principles, utilizing modular, scalable, technically reproducible and permissionless ways to identify, secure, version, derive, manage, find, retrieve, store, and mark outdated individual digital objects. Verifiable and cryptographically secure provenance for the ownership, signature, and version tracking availability are added benefits of the dPID technology. The other point of this ambitious initiative is the development of the toolset to obtain the described goals, keeping the sovereignty over the owned data, and yielding access control to external solutions. As a decentralized community advantage, there is also a goal to provide a possibility to voluntarily donate the resolution endpoints, storage, bandwidth and computational power, and build cryptographically assured trusted communities within the namespace of persistent identifiers.
Contacts of the dPID Initiative Group
- Group documentation and community resources (on Google Drive)
- dPID Google Group and Mailing List (managed by DeSci Labs)

Author: Erik Van Winkle
Date: 11 Mar, 2024
It's been interesting to see the evolution of this concept from disparate research groups over time into a cohesive PID system. (1, 2, 3, 4, 5). Also exciting to watch how more established PID systems are taking up the mantra of capabilities like "PIDs as importable resources" and "PIDs as the addresses for edge compute jobs". Definitely work to continue watching.